
What is Edge Computing and why should you care
A primer for an industry that is silently expected to grow to a $274B TAM by 2025 at ~15% CAGR

When I talked to various people about Edge Computing, the term “Edge” meant different to them, dependent on the sub-segment of the cloud/internet infrastructure industry they were part of. That was the impetus for this post, where I tried to showcase the broad spectrum of “Edge” nodes. More importantly, I have also tried to highlight some key infrastructure trends and developments that are currently ongoing under the surface, which will make Edge Computing a critical component of the industry’s IT spend. I hope this post gives investors and builders more insight into this space and what is coming in the next 5-6 years. This post covers the basics as a primer on Edge Computing, but if you need a deeper dive, the references I listed below are fantastic.
Structure of the post:
TL;DR
Where did it all start?
What is Edge?
What is Edge Computing?
Why Edge Computing?
Why now?
Market size and forecast
Market Map
Key areas of development, i.e., opportunities
TL;DR:
Edge computing doesn’t compete with cloud computing but will complement it; In tandem with Cloud, Edge will fulfill critical vectors such as low latency, data localization, edge analytics, etc., for specific use cases.
Edge doesn’t meaningfully take away Cloud's market share since Edge supports new use cases that are increasing the total TAM.
Although not as big as the Cloud transition, Edge computing will capture significant IT spending to cover critical use cases over the next decade.
Industry poses some key challenges, but vendors are rapidly innovating to address those challenges.
One important area/opportunity to keep an eye on is Edge databases - a key area of ongoing innovation.
Where did it start?
Edge computing can be traced back to the 1990s when Akamai launched its content delivery network (CDN), which introduced nodes at locations geographically closer to the end user. These nodes store cached static stateless contents such as images and videos. However, we have come far from there in terms of A. what Edge means and B. capabilities on the Edge, such as stateful, real-time, dynamic applications that can run on the Edge today.
What is Edge?
Let’s first explain Edge since there is a lot of confusion in the industry on the term “Edge”. I thought the diagrams below do a pretty good job of explaining a spectrum of nodes that can be called Edge. Edge can be defined from the regional data center Edge of a Cloud to all the way to the device edge. It highly varies based on the industry, use case, and capacity at that “Edge” node.

Source: Gartner
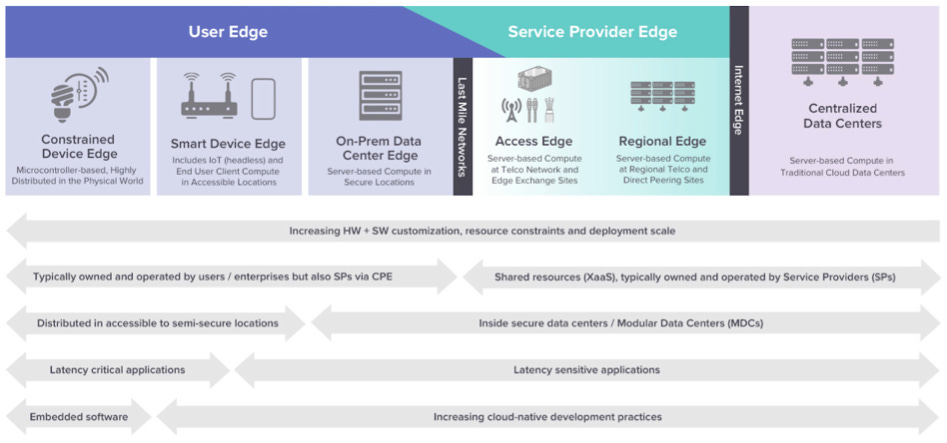
Source: LF Edge Whitepaper (The Linux Foundation)
What is Edge Computing?
Compute and Database are the nervous system and brain of Edge Compute. Now that we have defined what Edge is, let's take a quick look at how Compute has evolved and what sort of Compute we refer to when we talk about Edge Computing. On the one hand, as the definition of Edge has evolved, on the other hand, compute capacity and how Compute is spun up have changed drastically. For example, in the 1990's it took months to deploy a server where only one application could be hosted per server to fast forward to today, Serverless Compute can be spun up in seconds at the tip of developers' fingers.
Evolution of Compute

At a really fundamental level, you need three components to run an application: 1. Compute: To handle the dynamic nature of the app, 2. Database: To preserve and retrieve State, 3. Network: To deliver the app.
Now, as we know what Edge might mean and how Compute has evolved over time, Edge Compute can be defined when Compute runs on any of the Edge nodes from the above spectrum. Interestingly, any part of the Compute to support the use case/application can run on any nodes from Cloud/Origin to the end Client/Device.
The question then becomes what Compute should run on which node. The short answer is it depends.
Since the Edge node can mean anywhere from the “Regional Data Center Edge” of a Cloud to the “Device Edge”, one can use Containers, Kubernetes, Serverless Functions, etc., based on the use case, workload, and compute capability available on that Edge node. For example, in a latency-sensitive IoT use case, the Edge node can mean the “Device Edge”. While on the other hand, for a resource-intensive application that requires quite a lot of Compute power but still needs to be close to the users, the Edge node can mean the “Regional Data Center Edge”.
Cloud (“VS.” OR “+”) Edge Computing?
A quick diagram below explains this simply to hammer the difference between Edge Compute and Cloud Compute.
Edge Compute vs. Cloud compute

Source: Xenonstack.com
Edge computing will not replace or meaningfully cannibalize Cloud-enabled applications or demand for Cloud. Instead, crucial use cases such as latency and data sovereignty-sensitive applications will require this new layer computing network. The massive increase in data will drive demand for all data centers (Edge or Cloud). Based on the use case, the data will sit or get processed across the data center hierarchy above.

Source: Cowen Research
Why Edge Computing?
The figure below provides examples of many use cases that benefit from edge computing and related enabling technologies.
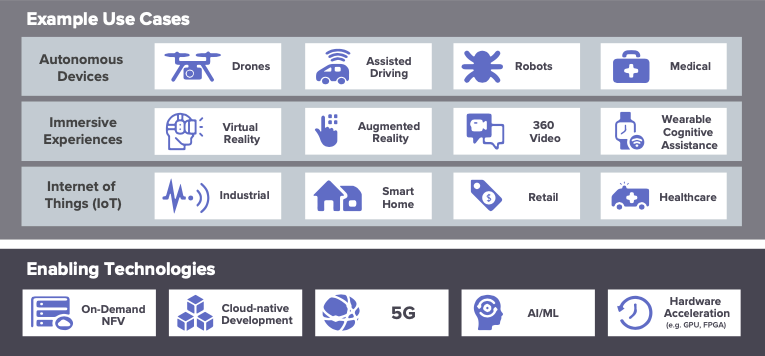
Source: LF Edge Whitepaper (The Linux Foundation)
There are many use cases above but what is interesting behind these use cases are the attributes that make Edge Computing an appealing option or sometimes the only option. Those attributes include Latency, Edge data analytics, Data localization, etc. Latency is often considered the most exciting factor that comes to mind. However, moving Compute to the Edge has other key benefits such as data sovereignty, bandwidth savings, data ownership, etc.
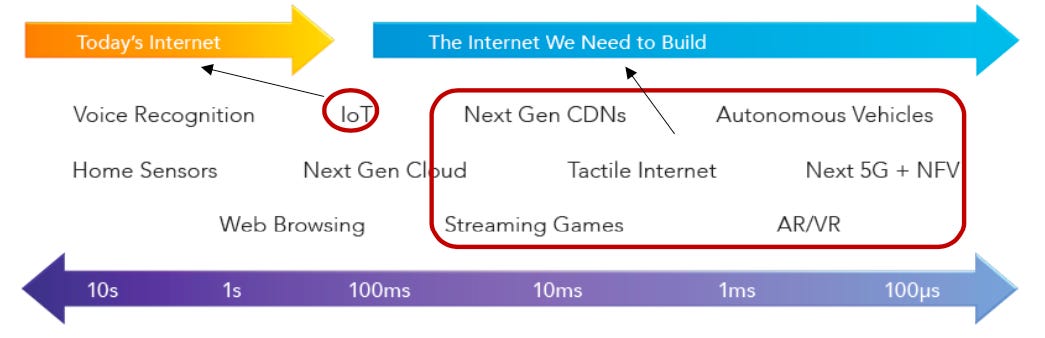
Source: Tolaga Research and The Linux Foundation “State of the Edge Report 2020”
Latency: When the Edge server is one responding instead of the origin server, Round-Trip Time (RTT) can be 10s of milliseconds instead of 100s of milliseconds. This difference is huge when we are talking about use cases such as advanced Gaming, AR/VR, or AI Inferencing. However, there are some critical dependencies with databases and how the entire app is orchestrated. More to be elaborated on that later.
Edge data collection and real-time analytics: A critical use case is data collection from a large set of IoT devices. Edge Compute solves two problems when compared to public cloud 1. Network: Sending large volumes of data over limited network connections to the origin where the origin might not be as responsive to handle as much data, 2. Cost: Sending a large volume of data back to the origin might not be cost-effective, especially when most of that data might not be valuable and need to be filtered through. Having the minimal Compute required on each device lets the device do basic analysis on the spot specific to that device and only send the necessary data back to the origin. It solves the above two problems since the aggregated volume of data back to the origin is significantly lower.
Data localization: With crucial regulations such as GDPR and Schrems II, Edge Compute can satisfy key mandates of these regulations via keeping the user or proprietary data in question in specific geo or localization to meet these compliance requirements such as geofencing, data sovereignty, copyright enforcement, etc. It also helps move the security elements of the data close to where the data originates. As a result, it improves the performance of the security operations and removes the risk of data breaches at the origin.
IoT: The Fourth Industrial Revolution (or Industry 4.0) is the ongoing automation of traditional manufacturing practices. Large-scale machine-to-machine communication (M2M) and the internet of things (IoT) are integrated for increased automation, improved communication and self-monitoring, and the production of smart machines that can analyze and diagnose issues without the need for human intervention. To fulfill the high-performance and low-latency communication needs, Edge Computing is necessary as at least some of the data processing, and filtering capabilities need to stay within the factory network.
Traffic monitoring as an example of an IoT use case
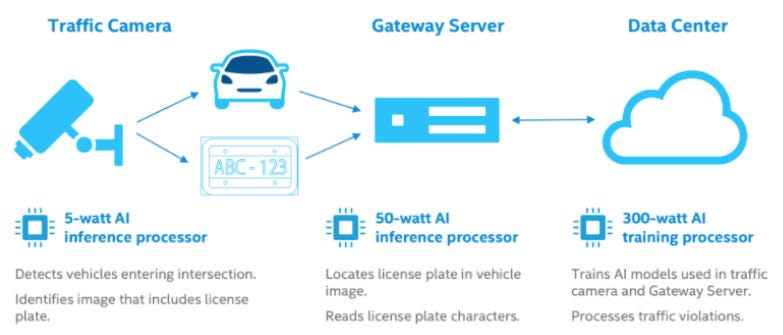
Source: Intel
Why now?
Location-based Edge computing is not new, but the explosive growth in the number of Edge devices is new. In addition, the trend compliments a broad array of advanced services and robust connectivity back to the Public Cloud. Also, following years of investments in AI training in the Cloud (model training in the Cloud), the AI industry is ready to put the AI models to work and shift investment to the next phase i.e., Inference at the Edge.
Gartner: Hype Cycle for Edge computing 2021 diagram

Source: Gartner
Data Explosion: As a massive amount of data is getting generated by the IoT devices, more and more data capture and processing needs to take place on the Edge of the network.
Public Cloud’s impact on AI: Catalyzing the AI industry, public clouds have put computing power, data storage, and software developers under the same roof allowing better economics and data sets for the AI models, thus better-trained models. As more and more “Inferencing” will be put into practice on the Edge, the demand for Edge Computing will also increase.
Parallel processing via GPUs in AI: The industry realized that GPUs could be used to accelerate AI workloads massively. It has led to a significant increase in AI training and, subsequently, inference.
Increasing Enterprise spending on AI: As companies realize the value AI can bring to their business, they (both hyper-scale players and traditional enterprises) are investing more in it.
Market size and forecast
The below forecast uses the power footprint of IT server equipment deployed at the Service Provider Edge as a primary measure to illustrate edge expansion. As part of the below forecast, LF Edge conservatively expects the global IT power footprint for infrastructure edge deployments to increase from 1 GW in 2019 to >40 GW by 2028, implying a CAGR of 40%.

Source: The State of The Edge Report 2021
Worldwide spending on edge computing is expected to be $176 billion in 2022, an increase of 14.8% over 2021. Enterprise and service provider spending on hardware, software, and services for edge solutions is forecast to sustain this pace of growth through 2025, when spending will reach nearly $274 billion, according to the International Data Corporation (IDC). IoT is a vital piece of that pie. IDC predicts that by 2025 there will be a total of 55.7 billion IoT (Internet of Things) devices, generating 73.1 zettabytes (ZB) of data worldwide. Adding to the need for edge computing, the amount of data generated outside the data center is exploding. Gartner, Inc. predicts that 75% of enterprise-generated data will be "created and processed outside a traditional centralized data center or cloud" by 2025.
Market Map
The edge ecosystem is still in its infancy. As Edge Computing matures to the next stage, it will require close industry collaboration across hardware providers, software companies, enterprises, CSPs, and Network Infra players. As Compute increasingly occurs closer to the end device, it is serving to help reduce latency and transport costs for critical use cases.
Cowen Edge Leaders Innovators and Key Companies

Source: Cowen Research
As seen on the map above, there are many components of Edge computing - let’s talk about Software at the Edge. Software is at the heart of edge computing. It consists of how applications are delivered, edge hardware is managed, and workloads move around networks. The ecosystem is building a new stack to run at the Edge of our networks.
Serverless is a key area of development in this bucket.

Source: Cloud Native Computing Foundation (CNCF.io)
Serverless Computing refers to a new model of cloud-native Computing enabled by architectures that do not require server management to build and run applications. Serverless functions instantiate quickly and hide a lot of the complexity needed to manage the underlying server and orchestration layers. Serverless and function-as-a-service (FaaS) platforms are especially well-adapted for running ephemeral edge computing workloads. The above landscape illustrates a finer-grained deployment model where applications, bundled as one or more functions, are uploaded to a platform and then executed, scaled, and billed in response to the exact demand needed at the moment.
Spend on the Edge Computing software segment would reach ~$20B by 2028.
Software spend forecast on Edge Computing ($M)

Source: Cowen research and Gartner research
Key areas of development, i.e., opportunities
Putting workloads on Edge means adapting how we build and run applications. While Edge deployments are similar to how we handle Computing across the rest of the network, the Edge also presents new challenges that we need to confront. Examples of these challenges are managing highly distributed applications/data and orchestrating edge operations at a significant scale.
The Edge Stack:
1. Systems Layer: At the lowest level is the systems layer, populated by operating systems and hypervisors providing the technologies needed to work directly with edge hardware.
2. Implementation Layer: The next layer encompasses implementation and management. Tools like VMware’s vSphere and Microsoft’s AKS are filling the gap to provide the services needed to support modern applications.
3. Tooling Layer: At the top sits tooling designed to deploy and operate applications for a great developer experience, such as Continuous Integration and Continuous Deployment (CI/CD) pipelines and methodologies such as GitOps. These tools provide a layer that helps effectively manage distributed applications at the scale needed for edge networks.
Across all three above layers sits the observability layer necessary to monitor critical KPIs for relevant stakeholders. Key developments are ongoing across all three layers above that accelerate Edge deployments.
Workload Orchestration:
As part of Edge Computing, running real-time workloads across the highly-distributed infrastructure introduces many complicated challenges to developers and operators. In addition to the typical scheduling attributes such as requirements around the processor, memory, operating system, etc. Edge workload orchestration might also have to deal with attributes such as Geolocation, Resiliency, Network Congestion, Bandwidth, etc. Many orchestration technologies, open source and otherwise, have emerged to tackle these complex scheduling problems.
Ongoing challenges: Look out for vendors and startups who are solving these problems-
Database/State: Lack of right components, such as databases to manage state that can support complexity and scale of use cases. Many players are developing highly distributed and strongly consistent databases that can support a wide variety of use cases at the Edge.
Architectures: Lack of standard architectures, i.e., complete end-to-end solutions to cover use cases - currently, developers are having to stitch together multiple solutions.
Vendor Integrations: Lack of vendor integrations across tools to create a consistent developer experience.
Edge Migration: Still, there is no easy way to break up an application and move the relevant components to the Edge. It’s complex to do for existing applications but comparatively easier if building something from scratch.
Skills: Skills gap in the company as the tech stack and use cases are still emerging.
Conclusion
Edge Computing is not new, and the buzz in the ecosystem has been there for at least half a decade. The interesting part is to keep an eye on the underlying infrastructure maturing rapidly, making the use cases on the Edge more real. Think of it this way - the dog food delivery companies such as Pets.com failed in the 2000s dot-com bubble. However, dog food delivery companies with very similar business models succeeded in the mid-2010s.
So what was different the second time? 1. Internet Infrastructure, 2. User behavior.
Suppose we can use the same analogy here then as 1. Internet Infrastructure matures 2. The above challenges get addressed on the Edge stack, and 3. Enterprise-generated data outside traditional data centers or Cloud continues to explode, the above use cases are going to become increasingly real where the need for Edge Computing is going to be essential. So what we might be expecting is not an overnight climb but more of a gradual upswing over the next 5-6 years.