
How to fit a 3.5-billion-parameter LLM in a phone browser
The dtype tour, fp32 down to int4, and why every NPU on your phone was built for this trick.

A 350-million-parameter model is 1.4 gigabytes.
No browser will download that. No NPU will accept it. No phone has the runtime memory for it. And yet the in-browser AI demos that are starting to feel actually good — live caption, on-device translation, in-page semantic search — are running models that size and bigger.
The trick that bridges those two facts is quantization. It’s the lesson I just shipped as Lesson 6 of web-ai-bench, the curriculum I’ve been building to teach in-browser AI through working benchmarks.
The dtype tour
Every weight in a neural network is a number. Train the model and you get hundreds of millions of those numbers, stored at 32 bits each. Quantization rounds each weight to a coarser representation — and the model still works.
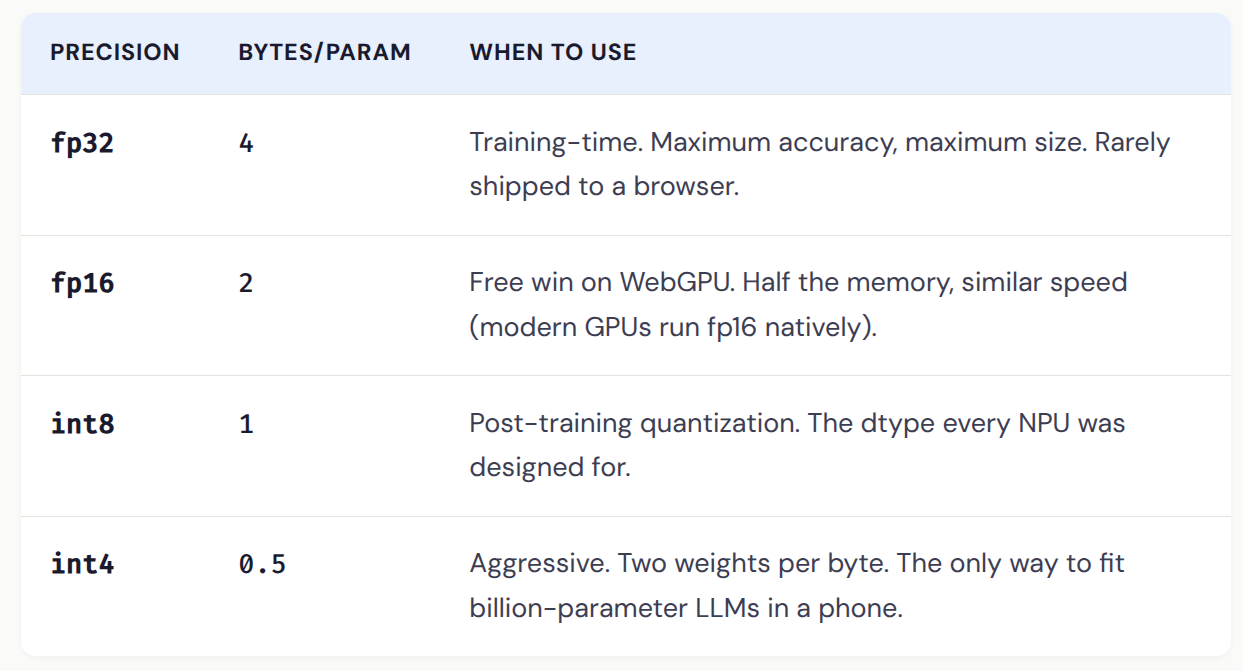
The same model at int4 is exactly 1/8 the size of the fp32 version.
That 1.4 GB model? At int4 it’s 175 MB. Now it ships.
NPUs reject fp32 on purpose
Every smartphone shipped in the last three years has a Neural Processing Unit — Hexagon, Apple Neural Engine, Tensor TPU, MediaTek APU. They don’t run fp32. By design.
Floating-point math is general-purpose but expensive in transistors and watts. Integer math at int8 needs a fraction of the silicon area and burns a fraction of the power. The NPU bet: quantize down to int8, get 10–100× speedup at ~10× lower power vs the GPU.
Which means: if you want your in-browser model to actually reach the NPU on a Pixel or a Snapdragon X Elite laptop, it has to be quantized. WebNN routes int8 models to the NPU through the OS’s ML driver. Send it fp32, it falls back to CPU.
Quantization isn’t a polish step. It’s the precondition for using the AI silicon you’ve already paid for.
Watch a 3.7B-param LLM shrink
The interactive lab in Lesson 6 lets you pick any of 12 catalog models and watch the bars shrink. For all-MiniLM-L6-v2 (the default sentence embedder) the bars are 23 MB → 12 MB → 5.8 MB → 2.9 MB. Cute, fits anywhere.
Here’s what happens with Phi-3.5-mini:
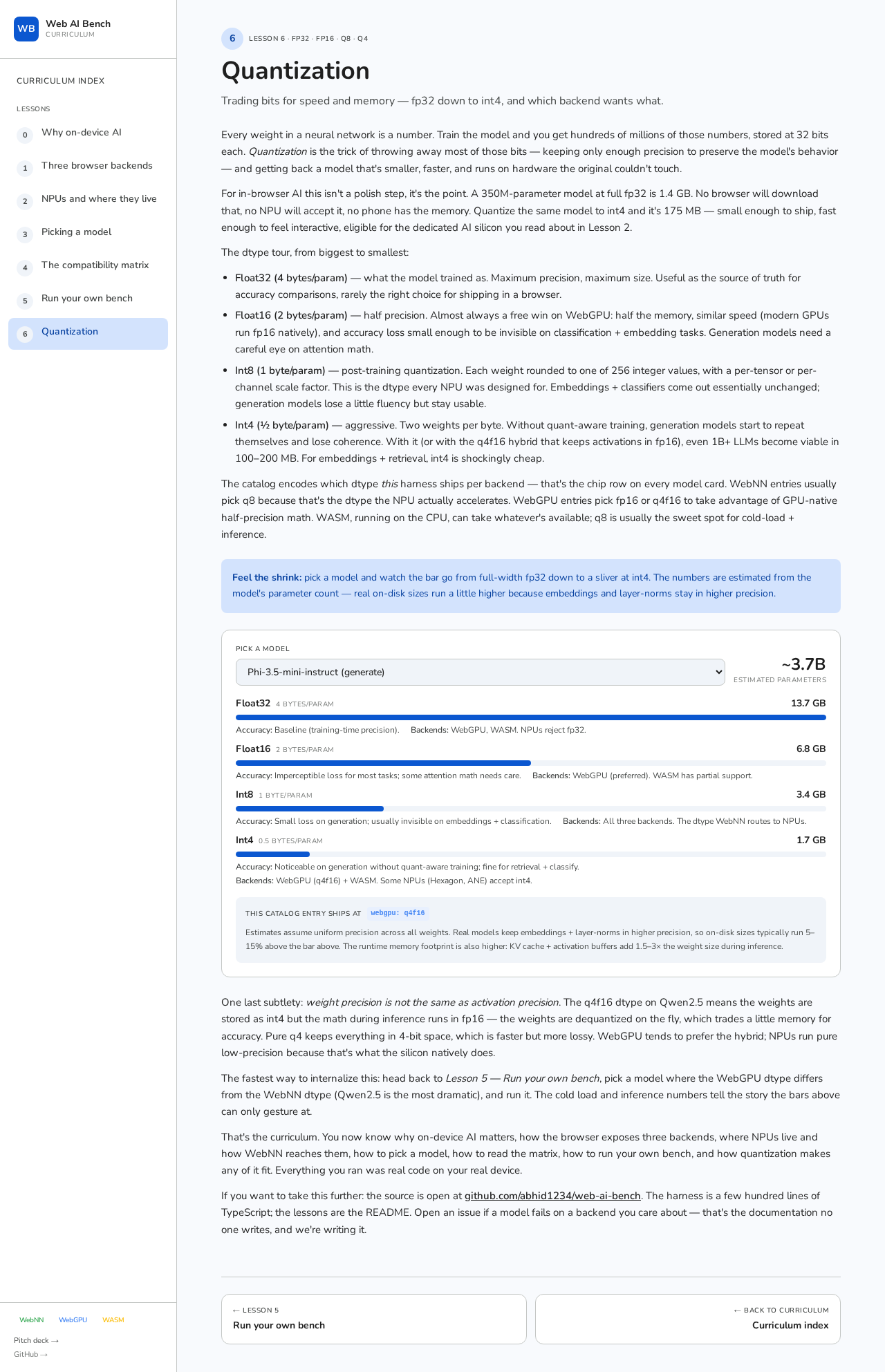
3.7B params. The bars are now in gigabytes
3.7 billion parameters. 13.7 GB at fp32. 1.7 GB at int4. Same model, eight times smaller. The fp32 version is unshippable; the int4 version downloads in under a minute on good wifi and fits comfortably in a recent phone’s memory.
By the time you’re at int4 you’ve thrown away 7/8 of every weight and the model still works.
Also: built for thumbs
While shipping the lesson I redesigned the whole curriculum for phone screens. Skip-to-lab pill on every page, card grids replacing dense bullet lists, 17px body type on mobile, reading times on every header, prose tightened by ~30%. The labs were always the point — the redesign just makes that obvious on a 360px viewport.
Try Lesson 6 yourself
Pick a model, watch the bars shrink. Free, open source, no signup.